今天分享的目标是少样本目标检测(few-shot object detection,FSOD)——仅在少数训练实例的情况下为新类别扩展目标检测器的任务。引入了一种简单的伪标记方法,从训练集中为每个新类别获取高质量的伪注释,大大增加了训练实例的数量并减少了类不平衡;新提出的方法会找到以前未标记的实例。
使用模型预测进行Na¨ıvely training会产生次优性能;研究者提出了两种新方法来提高伪标记过程的精度:首先,引入了一种验证技术来删除具有不正确类标签的候选检测;其次,训练了一个专门的模型来纠正质量差的边界框。

在这两个新步骤之后,获得了大量高质量的伪注释,允许最终检测器进行端到端的训练。此外,研究者展示了新方法保持了基类性能,以及FSOD中简单增强的实用性。在对PASCAL VOC和MS-COCO进行基准测试时,与所有shots数量的现有方法相比,新提出的方法实现了最先进或次优的性能。
目标检测是指确定图像是否包含特定类别的对象的任务,如果是,则对它们进行定位。近年来,通过为一组预定义的目标类训练计算模型,在目标检测方面取得了巨大的成功,其中包含大量人工注释标签,例如MS-COCO和PASCAL VOC。然而,这样的训练范式限制了模型只能在有大量训练数据的封闭的小类别上表现良好。
相比之下,人类可以不断扩展他们的词汇表,学习检测更多的类别,即使只能访问几个例子。这也是现代计算机视觉系统的理想能力,并在少样本目标检测 (FSOD) 任务中进行了研究。
研究者工作的目标是FSOD:给定一个现有的目标检测器,该检测器已经在某些类别的大量数据(称为基本类别)上进行了训练,我们希望学习仅使用一些注释来检测新类别,例如每个类别1-30个,同时保持原始基本类别的性能。
Problem Definition
在今天分享中,我们考虑与TFA[Few-shot object detection via feature reweighting]中相同的问题设置。具体来说,假设我们有一个图像数据集D和两个注释集。首先是 Ybase,对一组基本类别Cbase进行了详尽的注释。其次YKNOVEL,在一组小类别 CNOVEL上只有K个注释。请注意,基本类别的注释是详尽的,但对于新类别,大多数实例都没有标记,因为在少样本设置下,仅为图像数据集D提供了K个注释。
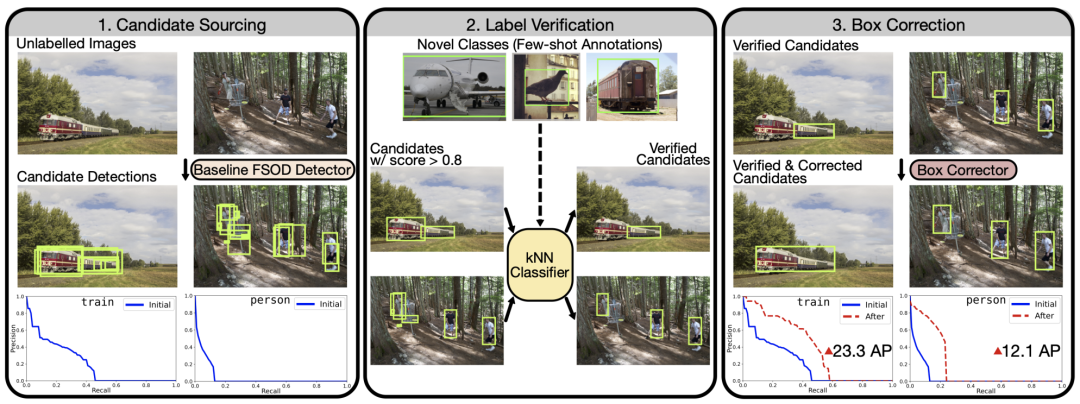
为了解决“监督崩溃”的问题,我们采用了一种简单的伪标签方法来挖掘新类别的实例,有效地扩展了它们的注释集。然而,来自检测器的伪注释(在Novel训练之后)是不可靠的,包含大量误报。在这里,我们建立了一种方法来提高这些候选伪注释的精度,方法是自动过滤掉具有不正确类标签的候选,并为剩余的那些改进边界框坐标。我们的方法为新类别产生了大量高精度伪注释,允许最终检测器在基础和新类别数据上进行端到端训练。
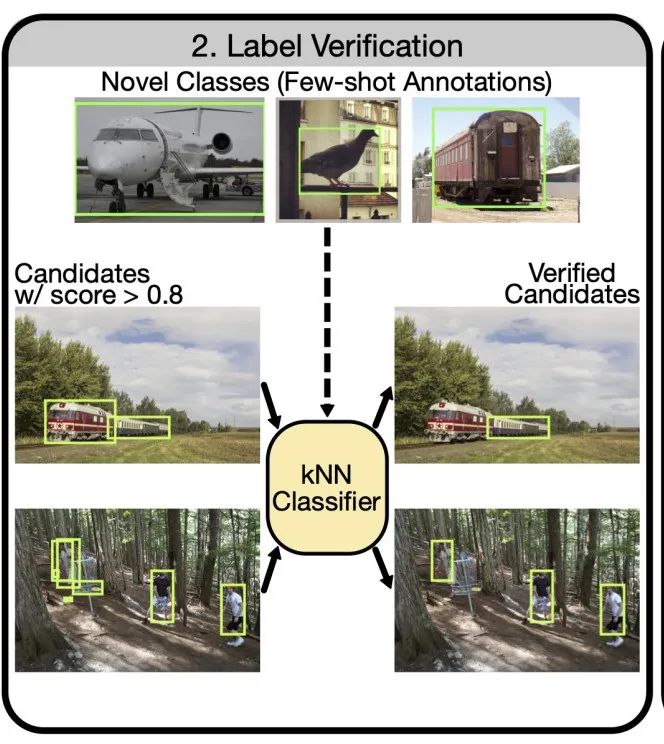
主要讲解下Label Verification!我们从Chum等人的查询扩展工作中获得灵感[Total recall: Automatic query expansion with a generative feature model for object retrieval]。它使用空间验证在检索期间接受或拒绝新实例。这里的目标是验证每个候选检测的预测类标签。具体来说,我们考虑为具有非常有限的few-shot注释的新颖类别构建分类器。仅使用少量注释构建分类器显然不是一项简单的任务,因为它通常需要高质量的特征表示。在这里,我们受益于自监督模型的最新发展,例如MoCo、SwAV、DINO,并使用这些模型产生的高质量特征构建kNN分类器。在实践中,这项工作使用了通过自监督DINO方法训练的ViT模型的输出CLS,其中NN性能被证明特别强。
为了执行标签验证(上图),我们首先使用自监督模型计算每个给定的新类 ground-truth注释的特征。这些特征在kNN分类器中用作训练数据。同样,我们使用相同的自监督模型计算候选检测集中每个实例的特征。具体来说,为了计算给定注释/候选检测的特征,首先使用边界框来裁剪相关图像。然后调整该作物的大小并作为输入传递给自监督模型。
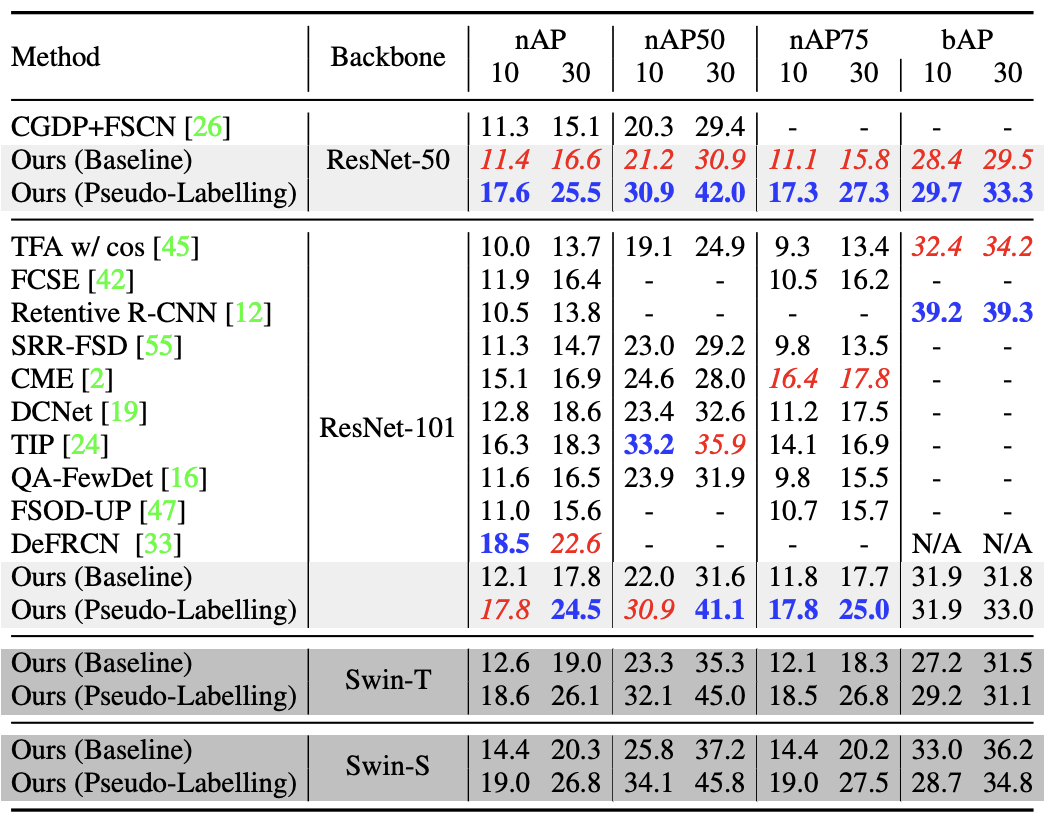
COCO数据上的性能比较
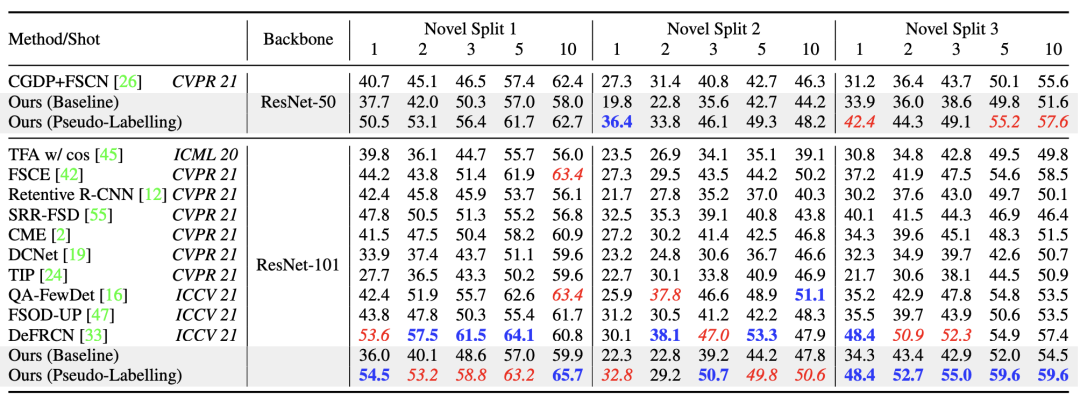
PASCAL VOC性能比较

左上:在标签验证期间验证的预测实例;来自我们的基线检测器和我们的kNN分类器的预测类标签匹配。右上:在标签验证期间被拒绝的预测实例;我们的基线检测器(误报)和kNN预测的类标签不匹配。左下:经过验证的质量非常差的边界框)蓝色虚线)在框校正期间得到了显着改善(石灰实心)。右下:经过验证的可接受的边界框(蓝色虚线)得到进一步改进(石灰实心)。
